We all know that managing data in our application is oftentimes a chore, as they require:
- Separate Front-End clients to manage various platforms such as Web, Mobile (iOS, Android, etc.), and more often than not, those clients require different sets of data
- A Back-End system that might source data from various storage entry points such as PostgreSQL, Redis, Firebase, etc.
- Complex State & Cache Management on both sides of the stack (Front-End & Back-End)
- Separate documentation for the queries
Fortunately enough, there is a more modern way of managing those chores, which comes in the form of GraphQL.
So, you might be asking, what exactly is GraphQL? Well, we’ll jump right into this topic.
What is GraphQL?
GraphQL has been initially coined as an API mechanism to handle complex querying tasks at Facebook which would not only be easy to learn how to work but also a good way to speed up the development of new products that would heavily rely on data and communication between various systems. (Hence it is pretty common to be used in Service-Oriented & Microservices Architectures)
A good example among Facebook’s use cases would be its mobile applications such as Facebook and Instagram.
So, basically, at its core, GraphQL is a query language that provides two-way instructions to both the Front-End and the Back-End on how to send and retrieve data.
That means that it allows Front-End Developers to request the exact data that they need from a pool of accessible data entries, which is far more convenient than having to define a new endpoint each time the client requires a new specific batch of data, as a solution to the classic Underquerying and Overquerying issues.
How does GraphQL work?
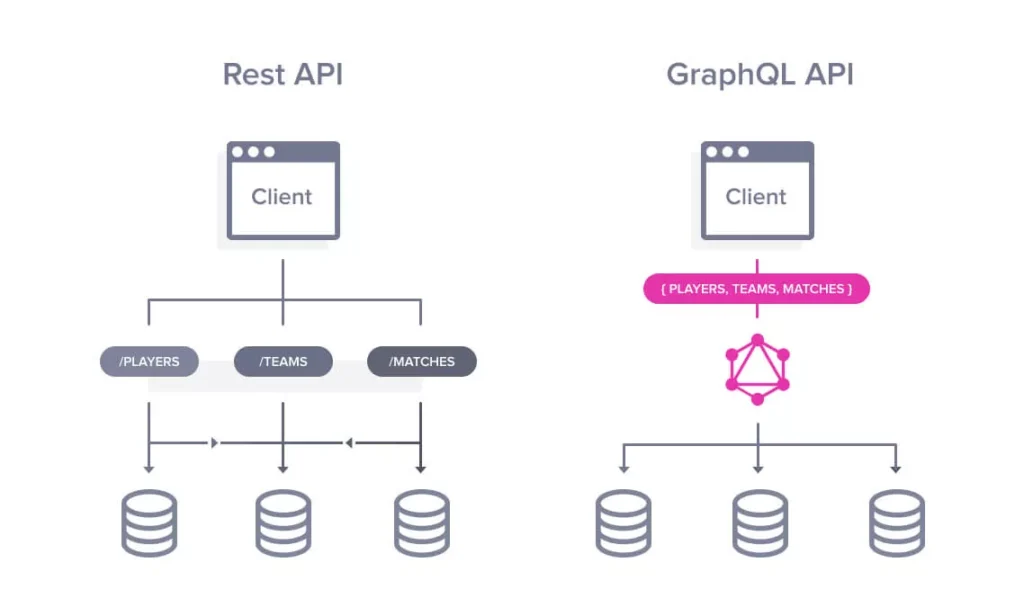
GraphQL acts as a wrapper around the connection between the client and the server and thus, it provides a single endpoint for your client to access the pool of data from the server and pick whatever they might need.
Not only that, but it also provides multiple entry points for the data to come in, so we might be able to access data from a variety of sources, which is extremely convenient when taking into account ease of integration with already existing services within a system.
In terms of the abstraction that GraphQL uses, we would be referencing that GraphQL interprets data points/models as Nodes, whilst the relations between those nodes would be referenced as Edges. Thus, the data is represented as a graph of interconnected objects/data points rather than resources we would otherwise access through RESTful endpoints. The whole graph is what we call The Application Data Graph.
GraphQL vs RESTful APIs
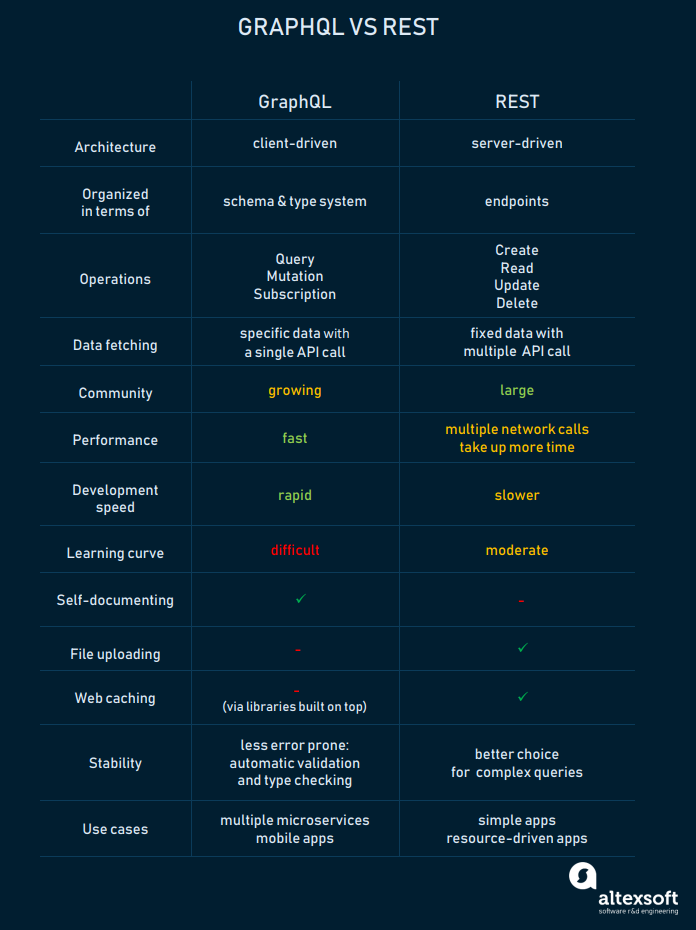
Advantages:
1. Speed
GraphQL is way faster than any other communication API as it forces you to cut down your request query by choosing only the specific fields you want to query, which solves the aforementioned issues of Underquerying and Overquerying.
2. Best for complex systems
It is best suited for complex systems such as those implementing SOA or Microservices Architectures, as it allows merging all of the system’s services under a single umbrella, which means that the data will be more easily accessible throughout the entirety of the system, which, as mentioned before, is extremely convenient.
3. Hierarchical Structure Approach
GraphQL follows a hierarchical structure where relationships between objects are defined in a graphical structure. Here, every object type represents a component, and every relationship field from an object type to another object type represents a component wrapping another component.
4. Shaped Data For Clients
Adds a shape to our data. When we request GraphQL queries to the server, the server returns the response in a simple, secure, and predictable shape. So, it facilitates you to write a specific query according to your requirement. This makes GraphQL really easy to learn and use.
5. Client/Server Agnostic
Since GraphQL is a protocol, it doesn’t care what technologies you are using on the Front-End or the Back-End of your application as long as there is support for implementing a GraphQL Client to handle the protocol implementation. For example: Apollo for JavaScript, Hot Chocolate for C#/.NET, etc.
Cons:
1. Query Complexity
When we have to access multiple fields in one query, regardless of it being requested RESTfully or through GraphQL, the varied resources and fields still have to be retrieved from a data source. So, it also shows the same problems when a client requests too many nested field data at a single time.
So there must be a mechanism like maximum query depths, query complexity weighting, avoiding recursion, or persistent queries to stop inefficient and breaking requests coming from the client side.
2. Caching
It is more complicated to implement a simplified cache with GraphQL than to implement it in REST. In REST API, we access resources with URLs, so we can cache them on a resource level because we have the resource URL as an identifier.
On the other hand, in GraphQL, is very complex because each query can be different, even though it operates on the same entity. But most of the libraries built on top of GraphQL offer an efficient caching mechanism.
GraphQL Glossary of Common Terms
- Query: A read-only operation to get data from the GraphQL service.
- Mutation: While a query could be designed to do data writes, this is not recommended. An explicit mutation is recommended.
- Field: The basic unit of data that we can obtain. GraphQL is in fact about selecting fields on objects. You can think of fields as properties of data models that you wish to query or mutate.
- Fragment: A set of fields that can be reused across multiple queries.
- Argument: Every field and nested object can have an argument, thus enabling us to filter or customize the results. Arguments are basically key:value pairs that we can use to filter data.
- Alias: To avoid naming conflicts in the results, aliases are useful. For instance, we can query the same object with different arguments and get the results in different aliases.
- Directive: This can be attached to a field or fragment to dynamically affect the shape of data. Mandatory directives are
@includeand@skipto either include or skip a field based on a condition. Directives are commonly used for pagination.
Final Word
I believe that GraphQL is a great way of managing more complex systems which it’s likely to be encountered when working with bigger applications.
If you encounter yourself in a situation where you see yourself trying to orchestrate a relationship between various Front-End clients, and/or multiple Back-End data entry sources, it might be a good indication that GraphQL might be a good fit for your use case.
In case you want to see how we are going to set up a GraphQL server with Node.js & Express you can check out this article here. If you also want to see how we are going to implement GraphQL through Apollo Client in our React application and interact with the GraphQL server, you can check this article.
If you feel like I’ve missed anything, or you’d like to further discuss anything I’ve mentioned in this article, feel free to leave a comment so we can pick it up. That would be highly appreciated.
Cheers!
💬 Leave a comment